How AWS taught SSD's to sprint the marathon with DynamoDB
Graham spends a lot of his time tuning and finding the cause of performance issues on some of the largest WebSphere Portal installations. Inevitably during our recent conversation we turned the topic to SSD’s, and performance considerations of database workloads atop.
Interestingly the most visible SSD proponent and database service is none other than Amazons AWS service DynamoDB. Launched earlier this year, a database service which can be scaled at the turn of the knob, whilst offering performance, availability and the NoSQL feature-set. Considering the whole premature klonking-out with small-block, highly-randomised IO that hits the SSD controllers, you’d think a very ambitious undertaking.
SSD’s are great, but not a panacea for all workloads, in their raw state; especially for write-skewed database workloads. One of the largest causes of headaches for SSD Controller manufacturers and those looking to optimize workloads on SSD’s is Write Amplification, otherwise known as the variable amount of operations or re-writes of the original size that have to occur before a write is actually processed / stored by the disk.
The conversation reminded me of a post by Todd Hoff who attended an AWS session of “DynamoDB for Developers”, and wrote :
Initially they ran into performance problems due to SSD garbage collections cycles
This is inevitable. In my VMUG talk from last week, I refer to the Controller, and rather its FTL (Flash Translation Layer) as the black box of the device, where all the secret sauce of the unit lives. This isn’t by mistake, as all the IP around the type of algorithms to use for wear levelling, garbage collection or any internal process resides within.
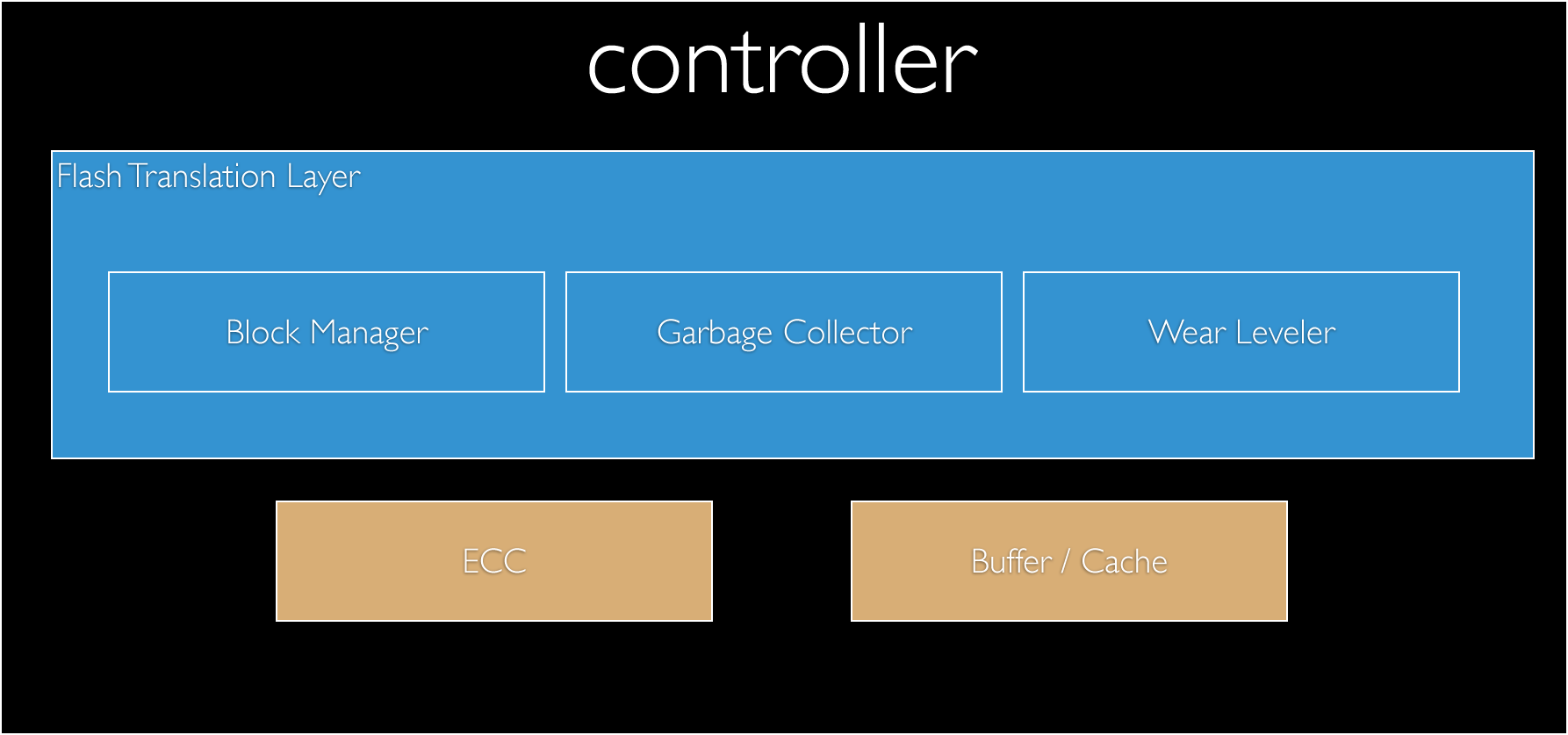
A single SSD within a single host, can cope with a lot of write-abuse, as given even a few minutes of ‘idle’ time, can effectively “defragment” its block + page layouts, and thus provide a buffer for the next onslaught. Although en-masse, where AWS operates, this simply will not work. As you will have many thousands of users and transactions in the hundreds of millions (+speculation), the drive will not have time to rest and carry out the vital to its survival, levelling and Garbage Collection.
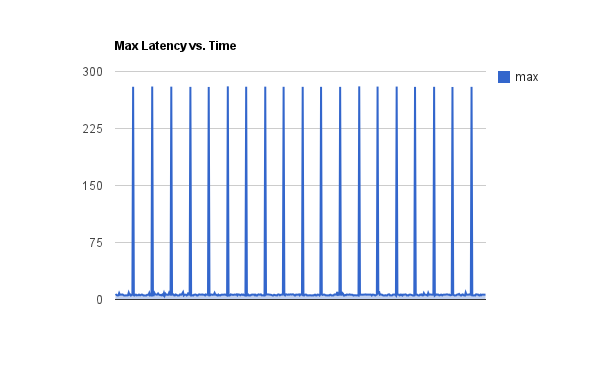
As the folk over at Tintri have shown, when SSD’s are pummelled to a point of saturation OR effectively outside the boundary of when the internal algorithms perform cleanup, the performance or rather the predictability of said performance is significantly diminished. Below you can see latencies of nearly 300ms for an SSD device.
When you’re operating a on a significant scale, you can’t have “unknown” hold you back, so that’s why (+speculative mode) Amazon worked directly with the manufactures of their SSD suppliers to have a say in:
- When and how GC kicks in
- RAID design across individual cells (similar to vRAID within Violin)
- Granularity of block mapping
- How blocks are read+cached+written, and aligned DIRECTLY for DynamoDB’s block-sized, in order to not necessarily alleviate, but minimise re-writes
- Locality of writes
The last being most interesting, and I believe an absolute must for the future of SSD to have an enduring life in the enterprise. Applications, or rather file-systems and thus API’s should allow for the ability to direct or at least specify the inter-relationship of data being written. Simply dumping blocks and forgetting about them is simple, but has dire consequences for the life of the storage medium in this case. Surrounding writes, or data operations with meta about them allows for solutions such as DynamoDB to exist and flourish. This requires a very tight integration between the software and hardware. There’s a reason Apple is one of the largest NAND / SSD suppliers (direct to consumer) out there, and why they bought Anobit, the Flash-controller firm last year. Go ponder.