How to virtualize your office - without their knowledge
People complain that they don’t have enough machines, and when they need servers, they’re available. Two of the problems that were prevalent in my workplace. I set out to attempt to rectify this by firstly measuring the utilization rate on some of our busiest servers.
Instead of installing and managing software that monitored CPU/Memory/HDD/Network utilization, I merely converted the whole machine to a virtual one - and offered it as a replacement under the same IP to all the users. This was done with a quick P2V conversion of the server into a VMware image pushed to a dedicated IBM Blade server running ESX 4.0 - which had far more grunt than the originating server. A few tweaks on the DHCP server to assign the right IP to the new born, and we were away. NOTE: the usage shown is of the machine running on the Blade, not on its original hardware; I’ll come back to this later in the post.
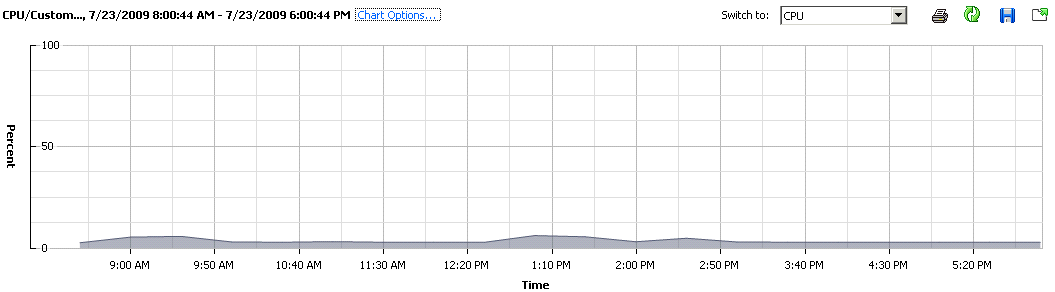
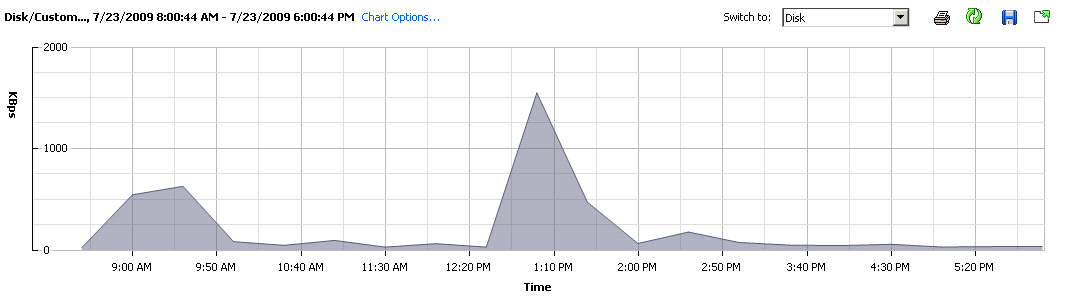
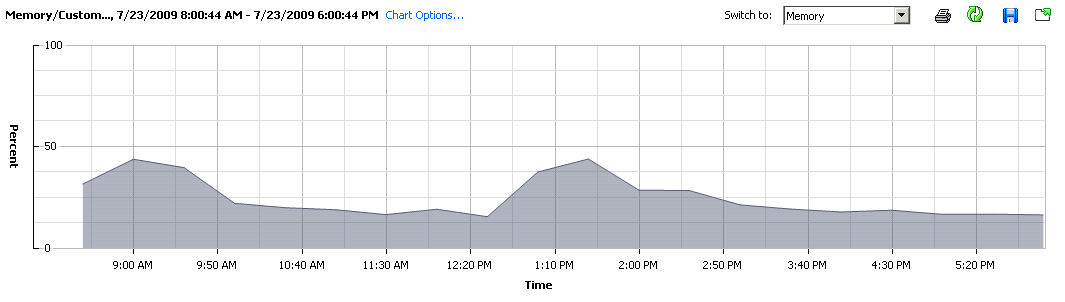
Before I continue, I’ll just tell you more about the software stack that is deployed on this specific machine. There is WebSphere + AppServer as well as a local instance of DB2. Mostly as you can see, its Java based, so memory usage will be fairly straight forward as it all gets eaten up on app start, and the variations that we see are from DB2. (I could use a remote DB and alleviate the memory variation all-together, which is something I will be doing with all deployments from now on).
Firstly now, the CPU Usage, throughout the day with constant use of the machine, averaged out to ~5%. Am certain this isn’t unheard of, for those that actual look at their data centres and the individual/un-optimized servers. Disk usage, aligns quite nicely with the Memory footprint, which once again points to DB2 doing its job.
So what can I improve here? - I can do several things:
- remove local DB, and deploy into a contained VM cluster, or just point it at a dedicated machine (which will also be a VM)
- if I offload the DB, I can increase the heap size within WebSphere for increased startup time, and overall performance
- put more machines onto this single Blade
Realising the first two points only after looking at the graphs (to write this post), I still haven’t implemented them. I did though - do the third.
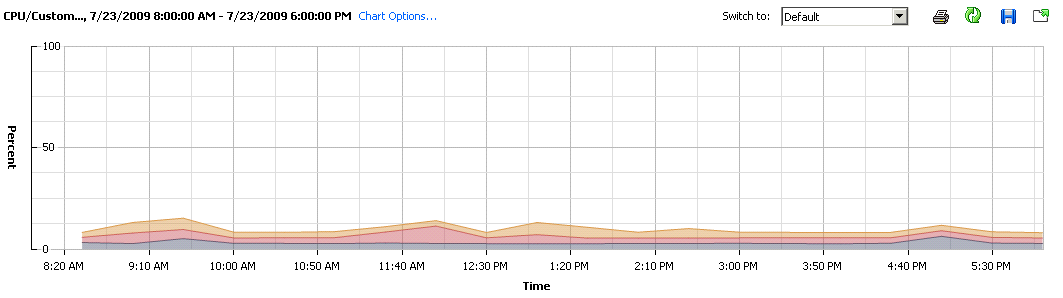
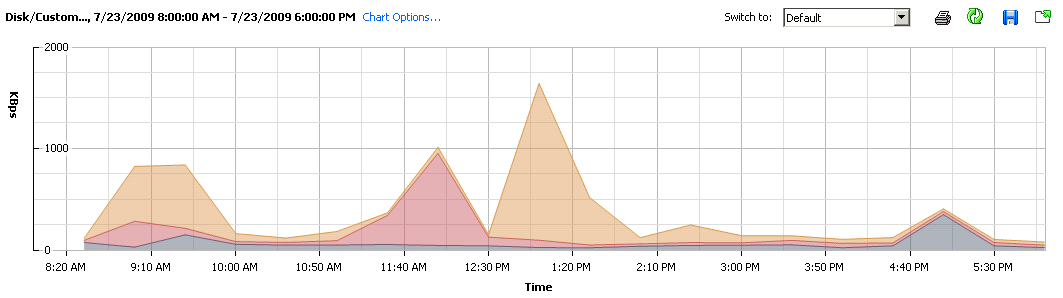
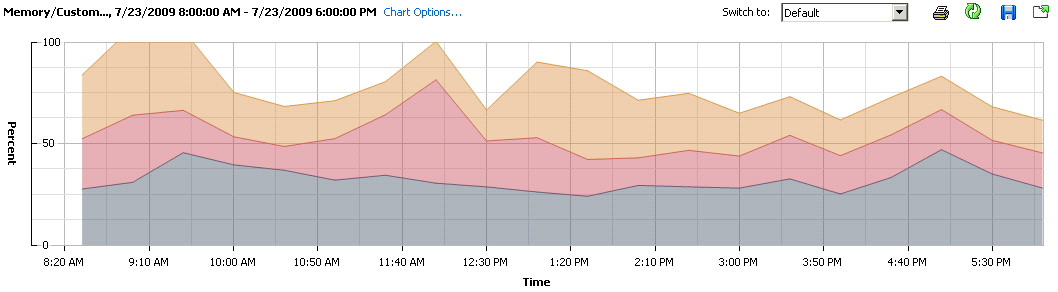
Very quickly you realise that although there’s an abundance of processing power, there’s just not enough RAM on the host blade. The ration of Ghz to Gbyte’s of RAM is about 3:1, instead it should be at the very least 1:1. Keep this a consideration next time have to put a new purchase order for more machines.
In the beginning of the post, I mentioned that the current blade host although more powerful than the original home of this software stack, it is far more scalable, and that is one of the reasons why I wanted to transfer and consolidate the numerous x345’s we have onto several blades. Most of the x345’s that were hosting servers are now turned off, the remaining few, I’m building a storage cluster with, to act as a iSCSI target server for the ESX’ed Blades.
What was satisfying was some people commenting on how fast the servers responded, little did they know that they were virtualized. Lesson: don’t buy 20 cheap and nasty servers, but a blade centre and start populating it as your budget permits.